Managing Meshes and Vertex Attributes
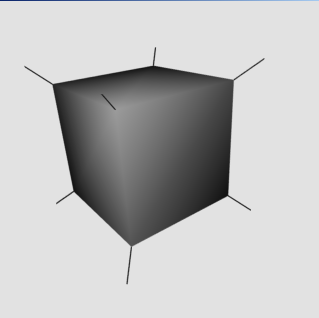
Mesh data often requires to have more than one normal for the same vertex.
Imagine a cube: It has eight different vertices, six unique normals (one for
each face) and only four unique texcoords. Even so, each vertex needs to be
rendered with three different normals, depending on which cube face it
is considered to be part of.
|
|
|
|
Wrong: Lighting with one normal per vertex, interpolated from
adjacent face normals.
|
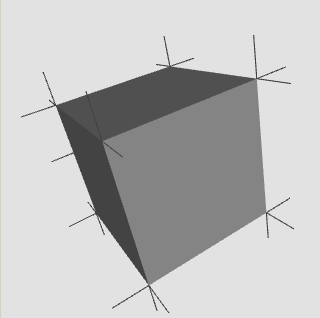
Correct: Each vertex is rendered with three different normals,
depending on which face is rendered.
|
Another fine mess, this time with texcoords: Each vertex only has one texcocord.
BUT: The vertices on the zero-median need two coordinates - 0.0 and 1.0.
|
|
In ancient days when rendering in immediate mode, this was not an issue.
You'd simply design your rendering loops to just provide one normal per face
instead of per vertex. But with modern OpenGL this is a no-go if you want to
see at least some performance.
The way to go with modern OpenGL is to cache as many data in objects residing
in GPU memory as possible. Typically, vertex buffer objects (VBOs) are used
to keep all kinds of vertex attributes, like coords, normals, colors, in GPU
memory. Index buffer objects (IBOs) allow to do the same for index data,
referring to the arrays of attribute vectors.
Unfortunately, the associated OpenGL render calls for indexed data, like
glDrawElements(), only support one index common to all attributes. This
means that a given index always refers to the same combination of coordinate,
normal, texture coordinate, etc. If you need to have different normals for the same
vertex, you need to duplicate the coordinate. For the cube example, this
boils down to render 24 vertices with 24 normals and 24 texture coordinates,
not using indices at all.
Handling multiple indices
|
Much like OpenInventor, tinySG allows to maintain a different index for
each of the (up to) 16 vertex attribute arrays, so each vertex can have multiple
normals, colors or texture coordinates. This strategy saves a lot of main memory
and is especially handy for mesh manipulations, because you manipulate one vertex
instance instead of several copies (just think of dragging one single vertex
instead of three identical copies needed to render three different normals at
that location...).
However, when uploading mesh data to GPU memory, tinySG "unrolls" all indices and
expands all attributes into an index-less, flat VBO to please OpenGL as mentioned
above. This
of cause means that the GPU memory footprint is in fact higher than in main
memory. A cube is then again made of 24 vertices, normals and texture coordinates.
Doing so also allows
to organise the data in an interleaved layout when submitting it to the
driver. This layout renders faster than arrays storing attributes sequentially
(all coordinates before all normals before...). As soon as the application applies
changes to the attribute or index data, the VBO is rebuilt and updated.
|
#Inventor V2.0 ascii
Coordinate3 {
point [
-1.0 -1.0 -1.0, 1.0 -1.0 -1.0, 1.0 -1.0 1.0,
-1.0 -1.0 1.0, -1.0 1.0 -1.0, 1.0 1.0 -1.0,
1.0 1.0 1.0, -1.0 1.0 1.0
]
}
Normal {
vector [
0.0 -1.0 0.0, -0.0 1.0 0.0, 0.0 0.0 1.0,
0.0 0.0 -1.0, -1.0 0.0 0.0, 1.0 0.0 0.0
]
}
NormalBinding {
value PER_FACE_INDEXED
}
IndexedFaceSet {
coordIndex [
0, 1, 2, 3, -1, 7, 6, 5, 4, -1,
3, 2, 6, 7, -1, 1, 0, 4, 5, -1,
0, 3, 7, 4, -1, 2, 1, 5, 6, -1
]
normalIndex [
0, 0, 0, 0, -1, 1, 1, 1, 1, -1,
2, 2, 2, 2, -1, 3, 3, 3, 3, -1,
4, 4, 4, 4, -1, 5, 5, 5, 5, -1
]
}
|
Calculating Per-Vertex Normals - Crease Angle
 Meshes exported from CAD applications often tend to span several "surfaces".
If vertex normals are calculated by just averaging face normals of all faces
the vertex is part of, the result is poor. The images on the right show the Bismarck
battleship dataset with just one averaged normal per vertex (top) and multiple
normals when the angle between two adjacent polygons is larger than 30 degrees
(bottom). Click on images to enlarge.
Meshes exported from CAD applications often tend to span several "surfaces".
If vertex normals are calculated by just averaging face normals of all faces
the vertex is part of, the result is poor. The images on the right show the Bismarck
battleship dataset with just one averaged normal per vertex (top) and multiple
normals when the angle between two adjacent polygons is larger than 30 degrees
(bottom). Click on images to enlarge.
Thus, most packages allow to define
a crease angle that defines the maximum angle between two face normals
for them to interpolate at a given vertex. If the angle between the face
normals is larger, then a crease is assumed to be in between the to faces and
multiple normals are created for the shared vertices.
 tinySG uses the following algorithm for calculating per vertex normals:
tinySG uses the following algorithm for calculating per vertex normals:
foreach face F of mesh:
foreach vertex V of F:
V.normal = (0,0,0)
foreach adjacent face Fa of V:
if angle(Fa.normal, F.normal) < creaseAngle:
V.normal += Fa.normal * Fa.area
else
; // ignore face normal
normalise V.normal
The vertex normals are kept as an array, a normal index for each vertex
references it's normal. The above loops produce as many normals for a vertex as
there are faces the vertex is part of, and usually many of them are identical.
So the next loop reworks the normal index and eliminates duplicate normals to
reduce the memory footprint of any csgIndexedShape node.
Performance
Indexing vertex data may deliver great performance, because graphics drivers or
even the hardware has a transformation cache, maintaining several already
transformed vertices. However, these caches are small (something around 10-20
vertices). Thus, the application needs to be careful about when to send which
index in order to take advantage of a vertex being found in the cache.
Having the transformation cache in mind, the following recent benchmark result
with tinySG came as a surprise: Unrolling the geometry of the Bismarck dataset
increased the render performance by up to 4x for synthetic benchmark datasets,
compared to indexed rendering using VBOs/IBOs.
The calls changed from glMultiDrawElements() to glMultiDrawArrays().
Both AMD/Ati and nVidia hardware benefit from the change.

|

|
|
|
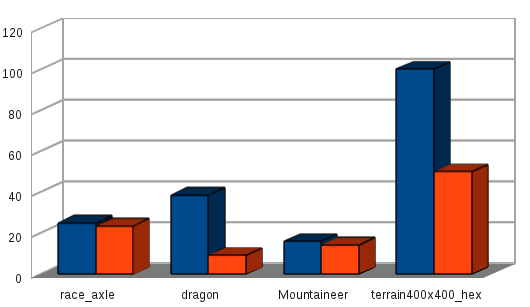
The Stanford Dragon: 0.87M triangles in 4 nodes.
|
Terrain dataset created with tinyTerrain generator: 400x400 hexagons,
1.3M triangles in 9 nodes.
|
Performance comparison: IBOs (red) vs. unrolled indices, flat attributes
(blue). Values show frames per second.
|
|
The table above shows a performance comparison done on a 2.8GHz Core i7-860
with an AMD FirePro W8000 running Windows 7. For large meshes (terrain,
dragon), performance gains by unrolling indices are huge. Real datasets
(axle, mountaineer) still show a significant improvement, although other
factors influence performance here as well, like 500-900 material state
changes, traversal of 1500-4000 scenegraph nodes and binding of well over
1000 VBOs each frame.
Keep rendering,
Christian
Acknowledgements:
- The model of the Bismarck battleship has been created by a chinese artist.
Unfortunately, I'm unable to reproduce the chinese characters here. The dataset
is available as a SolidWorks model at grabcad for non-commercial
use and has been exported to vrml to be loadable by tinySG.
- The earth texture is by courtesy of NASA.
- The dragon dataset is provided by courtesy of the Stanford Computer
Graphics Laboratory and kindly provided for research purposes and publishing of
rendered images.
- The terrain mesh was created with tinySG's tinyTerrain generator.
Copyright by Christian Marten, 2013
Last change: 15.11.2013
|
